
Chapter 4 Lesson 1 - Account Storage
Alriiiiighty then. We made it through 3 chapters. But there’s lots to go ;) Let’s do this.
Video
Watch this video up until 14:45: https://www.youtube.com/watch?v=01zvWVoDKmU
We will cover the rest tomorrow.
Accounts on Flow
If you remember back to Chapter 2 Lesson 1 when we learned about transactions, I also talked about accounts on flow and how they can store data. I’m going to copy and paste that below because it’s helpful to review:
On Flow, accounts can store their own data. What does this mean? Well, if I own an NFT on Flow, that NFT gets stored in my account. This is very different than other blockchains like Ethereum. On Ethereum, your NFT gets stored in the smart contract. On Flow, we actually allow accounts to store their own data themselves, which is super cool. But how do we access the data in their account? We can do that with the AuthAccount type. Every time a user (like you and me) sends a transaction, you have to pay for the transaction, and then you “sign” it. All that means is you clicked a button saying “hey, I want to approve this transaction.” When you sign it, the transaction takes in your AuthAccount and can access the data in your account.
You can see this being done in the prepare portion of the transaction, and that’s the whole point of the prepare phase: to access the information/data in your account. On the other hand, the execute phase can’t do that. But it can call functions and do stuff to change the data on the blockchain. NOTE: In reality, you never actually need the execute phase. You could technically do everything in the prepare phase, but the code is less clear that way. It’s better to separate the logic.
What lives in an account?
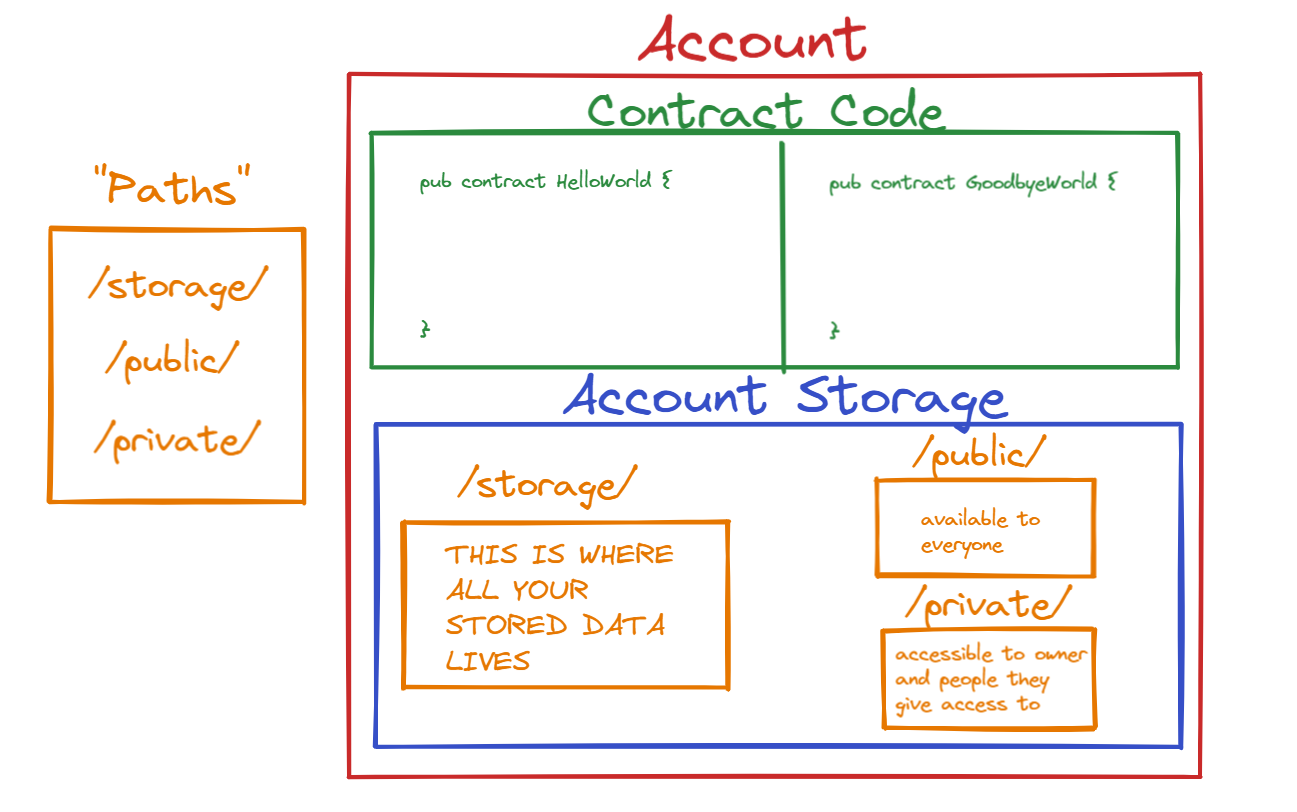
As you read above, on Flow, accounts actually store their own data. What this means is, if I have an NFT resource, I can actually store that in my own account. But where?
Using the above diagram (I’m so proud of it), let’s talk about what lives in an account:
- Contract Code - contract get deployed to an account, and live inside the account. Multiple contracts can live inside an account.
- Account Storage - all your data gets stored inside account storage
Account Storage
Well, what is account storage then? You can think of account storage as a “container” of data that lives at a specific path: /storage/. In a Flow account, there are 3 paths to get to certain data:
/storage/- only the account owner can access this (thank goodness, or someone could steal all of your data). ALL of your data lives here./public/- available to everybody/private/- only available to the account owner and the people that the account owner gives access to
The key part to remember is that only the account owner can ever access their /storage/, but they have the ability to place things in the /public/ and /private/ paths if they want to. For example, if I want to simply show you my NFT, I can put a readable version of my NFT in my /public/ path so you can see it, but restrict it just enough so you can’t withraw it from my account.
Hint hint: Do you see how resource interfaces may be useful here? ;)
You may be wondering: “well, how do I access my /storage/?” The answer is your AuthAccount type. If you remember, when you sign a transaction, the signer’s AuthAccount gets placed as a parameter in the prepare phase, like so:
transaction() {
prepare(signer: AuthAccount) {
// We can access the signer's /storage/ path here!
}
execute {
}
}
As you can see above, we can access the signer’s /storage/ in the prepare phase. This means we can do anything we want with their account. That is why it’s so scary to think of accidentally signing a transaction! Be careful folks.
Save and Load Functions
Let’s practice storing something in an account. First let’s define a contract:
pub contract Stuff {
pub resource Test {
pub var name: String
init() {
self.name = "Jacob"
}
}
pub fun createTest(): @Test {
return <- create Test()
}
}
We have defined a simple contract that lets you create and return a @Test resource type. Let’s get this in a transaction:
import Stuff from 0x01
transaction() {
prepare(signer: AuthAccount) {
let testResource <- Stuff.createTest()
destroy testResource
}
execute {
}
}
All we’re doing is creating and destroying a @Test. But what if we wanted to store it in our account? Let’s see how that’s done, and then we’ll walk through it:
import Stuff from 0x01
transaction() {
prepare(signer: AuthAccount) {
let testResource <- Stuff.createTest()
signer.save(<- testResource, to: /storage/MyTestResource)
// saves `testResource` to my account storage at this path:
// /storage/MyTestResource
}
execute {
}
}
Look at how we saved it to our account. First, we have to have an AuthAccount to save it to. In this case, we have the signer variable. Then, we can do signer.save(...) which means we’re saving something to a /storage/ path.
.save() takes two parameters:
- The actual data to save
- a
toparameter that is the path we should save it to (it must be a/storage/path)
In the example above, I saved testResource (note the <- syntax since it’s a resource) to the path /storage/MyTestResource. Now, anytime we want to get it, we can go to that path. Let’s do that below.
import Stuff from 0x01
transaction() {
prepare(signer: AuthAccount) {
let testResource <- signer.load<@Stuff.Test>(from: /storage/MyTestResource)
// takes `testResource` out of my account storage
destroy testResource
}
execute {
}
}
In the example above, we use the .load() function to take data OUT of our account storage.
You’ll notice that we have to do this weird thing: <@Stuff.Test>. What is that? Well, when you’re interacting with account storage, you have to specify the type you’re looking at. Cadence has no idea that a @Stuff.Test is stored at that storage path. But as the coder, we know that is what’s stored there, so we have to put <@Stuff.Test> to say “we expect a @Stuff.Test to come out of that storage path.”
.load() takes one parameter:
- a
fromparameter that is the path we should take it from (it must be a/storage/path)
One more important thing is that when you load data from storage, it returns an optional. testResource actually has type @Stuff.Test?. The reason for this is because Cadence has no idea that you are telling the truth and something actually lives there, or that it’s even the right type. So if you were wrong, it will return nil. Let’s look at an example:
import Stuff from 0x01
transaction() {
prepare(signer: AuthAccount) {
let testResource <- signer.load<@Stuff.Test>(from: /storage/MyTestResource)
log(testResource.name) // ERROR: "value of type `Stuff.Test?` has no member `name`."
destroy testResource
}
execute {
}
}
See? It is an optional. To fix this, we can either use panic or the ! operator. I like to use panic because you can specify an error message.
import Stuff from 0x01
transaction() {
prepare(signer: AuthAccount) {
let testResource <- signer.load<@Stuff.Test>(from: /storage/MyTestResource)
?? panic("A `@Stuff.Test` resource does not live here.")
log(testResource.name) // "Jacob"
destroy testResource
}
execute {
}
}
Borrow Function
Previously, we saved and loaded from our account. But what if we just want to look at something in an account? That’s where references and the .borrow() function comes in.
import Stuff from 0x01
transaction() {
prepare(signer: AuthAccount) {
// NOTICE: This gets a `&Stuff.Test`, not a `@Stuff.Test`
let testResource = signer.borrow<&Stuff.Test>(from: /storage/MyTestResource)
?? panic("A `@Stuff.Test` resource does not live here.")
log(testResource.name) // "Jacob"
}
execute {
}
}
You can see that we used the .borrow() function to get a reference to the resource in our storage, not the resource itself. That is why the type we use is <&Stuff.Test> instead of <@Stuff.Test>.
.borrow() takes one parameter (same as .load()):
- a
fromparameter that is the path we should take it from
Also note that because we aren’t using .load(), the resource is staying inside our account storage the whole time. Wow, references are awesome!
Conclusion
Let’s take a look at this diagram again:
As of now, you should understand what /storage/ is. In tomorrow’s chapter, we’ll talk about the /public/ and /private/ paths.
Quests
Explain what lives inside of an account.
What is the difference between the
/storage/,/public/, and/private/paths?What does
.save()do? What does.load()do? What does.borrow()do?Explain why we couldn’t save something to our account storage inside of a script.
Explain why I couldn’t save something to your account.
Define a contract that returns a resource that has at least 1 field in it. Then, write 2 transactions:
A transaction that first saves the resource to account storage, then loads it out of account storage, logs a field inside the resource, and destroys it.
A transaction that first saves the resource to account storage, then borrows a reference to it, and logs a field inside the resource.